
Hadoop
APACHE
HADOOP

Hadoop es una estructura del software de código abierto para almacenar datos y ejecutar aplicaciones de clústeres de hardware comercial. Proporciona almacenamiento máximo para cualquier tipo de datos, enorme poder de procesamiento y la capacidad de procesar tareas o trabajos simultáneos virtualmente limitados.
APACHE HADOOP

Hadoop es una estructura del software de código abierto para almacenar datos y ejecutar aplicaciones de clústeres de hardware comercial. Proporciona almacenamiento máximo para cualquier tipo de datos, enorme poder de procesamiento y la capacidad de procesar tareas o trabajos simultáneos virtualmente limitados.
INSTALACIÓN
INSTALACIÓN
Los siguientes son los pasos de la instalación del
framework Hadoop en Ubuntu 19.04. Hay que considerar que se realizara en una
máquina virtual hecha en Oracle VirtualBox:
1. Se instalara el sistema operativo de Ubuntu en la maquina virtual, por lo que para ello, se pueden seguir los pasos del apartado de "¿Como instalar Ubuntu en una maquina virtual?" disponible en la pagina "Virtualización de S.O."
2. Asimismo, se puede acceder a dicha pagina en este propio blog, a través del siguiente enlace: https://multysov2.blogspot.com/p/virtualizacion-de-sistemas-operativos.html
3. Al ser una máquina virtual creada desde
cero, en el proceso de instalación solo hay que dar en siguiente en todos los
pasos. En la sección de crear un usuario, se escoge el nombre del usuario y la
contraseña libremente.
El proceso de instalación dura alrededor de 10 a 15 minutos. Además, cuando termine, se deberá seleccionar en la opción de reiniciar el equipo. Cuando termine de cargar completamente el sistema, ya se podrá trabajar con el usuario que se creo.
4. Una vez que se haya instalado Ubuntu y de
que la maquina haya arrancado, se abre la terminal y se digita java –version. Con lo cual,
normalmente, dirá que no se tiene ninguna versión instalada, por lo que hay que
proceder a instalarla desde la terminal.


Una vez hecha la instalación, al escribir
nuevamente java –version se mostrara
la version del java que se tiene en la máquina.

5. Se crea un nuevo grupo de Hadoop y asimismo, se inserta dentro de dicho
grupo un nuevo usuario, el cual, será el usuario de Hadoop que se utilizara
desde ahora en adelante.

Se debe colocar todos los datos primordiales al
usuario de Hadoop o los que se considere necesarios.
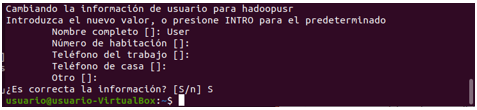
Por último, se le da ese nuevo usuario de
Hadoop los privilegios de administrador.

6. Se
instala el servidor de openssh

Esto se hace, ya que Hadoop utiliza SSH
para acceder a los nodos. En este caso, como se está haciendo una configuración
para solo un nodo, se necesita configurar el SSH para acceder al localhost.
7. Se entra como usuario de Hadoop, para
luego, generar la clave pública del SSH para el usuario de Hadoop.

Luego, se agrega la clave generada
anteriormente a la lista de llaves
autorizadas o authorized_keys.
Para ello, se ejecuta el siguiente comando:

E igualmente, hay que comprobar la
conexión al ssh localhost funciona
correctamente.
Para poder finalizar la conexión con el ssh localhost, simplemente se escribe exit.

8. Se debe descargar los archivos necesarios
para la instalación de Hadoop, los cuales, se pueden encontrar en la siguiente
página: https://archive.apache.org/dist/hadoop/core/hadoop-2.9.1/
Hay que decir que la versión que se va a
instalar será la 2.9.1.

Una vez que la descarga haya finalizado, se
copia el archivo y se pega en el Escritorio y una vez allí, hay que proceder a
descomprimirlo.

Primero, hay que desplazarse al Escritorio por
la terminal para luego, descomprimirlo con el comando sudo tar xvzf


9. Ya hecha la descompresión, se mueve la
carpeta generada al directorio usr /
local / hadoop y se le agrega la propiedad de la carpeta hadoop al usuario de hadoop

10. Ahora, se deben configurar algunos
archivos. La configuración de Hadoop comienza por la definición de las
variables de ambiente puestas en el archivo ~ / .bashrc

Tras escribir en la terminal el anterior
comando, se mostrara el contenido del archivo en la terminal.
Por ello, en la parte final del archivo,
se deben escribir las siguientes variables y exportaciones:

Se guarda, pulsando Control + O y para salir,
se pulsa Control + X. Una vez hecho esto, se debe escribir el siguiente
comando, para que la configuración que se acabó de hacer tenga efecto en la
sesión actual.

11. Después de eso, hay que desplazarse a la
carpeta de hadoop ubicada en usr / local
/ hadoop / etc / hadoop
Ahora, se tiene que editar los siguientes
archivos:

Hadoop-env.sh

Este último dependerá mayormente de la
versión de Java que se tenga, como en este caso se tiene la 11, por ello, se
coloca ese número. Además, hay que decir, que si en un futuro se da un error a
la hora de conectarse y levantar los servicios, debe ser porque alguna parte de
la dirección de la ruta está equivocada, ya que en vez de un JVM, es
simplemente jvm.
Core-site.xml

Hdfs-site.xml

Yarn-site.xml

El último archivo es mapred-site.xml,
pero, debido a que el nombre del archivo por defecto es,
mapred-site.xml.template, se tendrá que cambiar el nombre del archivo y
asimismo, copiarlo y pegarlo en la carpeta de hadoop, la carpeta donde el
usuario de hadoop está ubicado.
Para ello, se escribe el siguiente
comando:

Mapred-site.xml

12. Se crean los directorios para el namenode y el datanode:

Se debe agregar la propiedad de la carpeta
hadoop_space al usuario de hadoop.
Para luego, escribir cd, para salir
de la carpeta de hadoop.
13. Hecha todas las configuración y ya creados los
directorios de namenode y datanode, se formatea el namenode:

14. Hay que iniciar los servicios de hadoop, para
ello, se escriben los siguientes comandos:


Cabe recalcar que con escribir solo start-all.sh se inician todos los
servicios. Los dos comandos puestos anteriormente, son usados para hacer un
seguimiento de que todo esté funcionando correctamente.
Para saber qué servicios se iniciaron o se
levantaron, se escribe jps

Cabe decir que deben ser los 6 servicios
indicados anteriormente los que se deben iniciar, ya que, en otro caso, podría
haber problemas a la hora de usar mapreduce.
15. Al escribirse en la terminal, hadoop version, deberá mostrar la
versión de hadoop que se instaló:

16. Para finalizar, para acceder a la interfaz
gráfica de la gestión de hadoop, se deben tener los servicios arriba y en el
navegador hay que digitar la URL: http:
// localhost: 8088

REFERENCIAS
Sas.com. (s.f.). Hadoop ¿Qué es y por qué es importante? Sas.com Recuperado de https://www.sas.com/es_co/insights/big-data/hadoop.html
Ana Gómez. (Marzo 2019). Apache Hadoop – Instalación y configuración de un clúster en Ubuntu
18.04. Noticias RTV Recuperado de https://noticiasrtv.com/apache-hadoop-instalacion-y-configuracion-de-un-cluster-en-ubuntu-18-04/
MAPREDUCE
Es un marco con la que se pueden escribir aplicaciones para
procesar grandes cantidades de datos, paralelamente, en grandes grupos de
componentes de hardware de manera confiable.
MapReduce es una técnica de procesamiento y un programa
modelo de computación distribuida basada en java. El algoritmo MapReduce
contiene dos tareas importantes, Mapa y Reducir.
Mapa toma un conjunto de datos y lo convierte en otro
conjunto de datos, en el que los elementos se dividen en tuplas (pares clave/valor).
Reducir toma la salida de un mapa como entrada y combina los datos tuplas en un
conjunto más pequeño de tuplas. La reducción se realiza siempre después de que
el mapa.
PROGRAMA
DE EJEMPLO
Inverted
Index: Es un programa que reconoce las palabras iguales entre dos
archivos de texto que sirven como entrada, además, calcula el número de veces
que se repiten dichas palabras.
1. Se
crea una carpeta llamada InvertedIndex y esta se coloca en un lugar accesible
para el usuario, como es el Escritorio. Asimismo, dentro del directorio InvertedIndex
se crea una carpeta llamada Input y otra carpeta llamada Clases.

En la
carpeta de Input se colocan los archivos de texto, que contendrán los textos a
analizar (los archivos de texto pueden contener lo que desee el usuario, siendo
en este caso sample1.txt y sample2.txt), mientras que la carpeta de Clases, por
el momento se mantiene vacía.


2. Se
abre un editor de texto y se escribe todo el código del programa, para luego
guardarlo con la extensión .java. Sin embargo, si no se conoce la forma de
realizar este programa, se puede encontrar el código en Github: https://github.com/caizkun/mapreduce-examples/tree/master/InvertedIndex

Lo
único que se tiene que hacer es copiar cada uno de los códigos que se
encuentran en la carpeta de src/main/java y pegar cada uno en un editor de
texto y guardarlo respectivamente con la extensión de .java, para luego
colocarlo dentro de la carpeta de InvertedIndex que se creó.



3. Se
abre la terminal y se inician todos los servicios como usuario de hadoop. Con
el comando start-all.sh para luego
confirmar que servicios se iniciaron con jps.
4. Para
asegurar que el javac esté funcionando correctamente, se escribe el comando javac –version

5. Se
envía el ambiente de la variable de HADOOP_CLASSPATH
con el comando de export y para
confirmar su envió se utiliza echo.

6. Se
crea el directorio en el HDFS, es decir, en el gestor de hadoop, para luego, en
el mismo gestor crear la carpeta de entrada.

Para verificar que los
comandos anteriores fueron ejecutados correctamente, hay que desplazarse a la
URL: http: // localhost: 50070

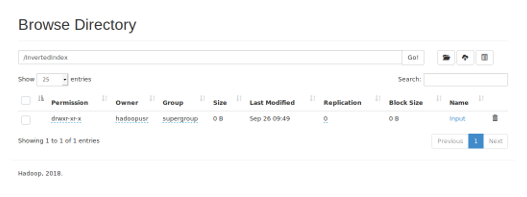
Lógicamente, en su interior no
habrá nada, ya que, todavía no se ha puesto el archivo de texto. Para ello, se
utiliza el siguiente comando:

Es
decir, se colocan los dos archivos de entrada en el directorio creado en el
gestor de hadoop.
7. Hay que desplazarse al directorio InvertedIndex

Una
vez allí, se crean las clases, en la carpeta llamada Clases que se creó en los
primeros pasos, para ello:

Como se puede observar, tras
escribir el comando, aparecerá un error, para solucionarlo, hay que darle todos
los permisos a la carpeta de WordMean y al archivo java. Se abre una nueva
terminal y se digitan los siguientes comandos:

Tras
dar los permisos, se digita nuevamente el comando de javac y de esta manera, ya
no aparecerá ningún error.

Además,
tras digitar el comando, las clases del InvertedIndex estarán dentro de la
carpeta clases.

8. Ahora, hay que generar el archivo .jar, el cual, será el
archivo necesario para dar la salida.

Hay
que destacar que el nombre dado por el jar puede ser dado por el usuario
libremente.
Sin
embargo, se le tiene que colocar todos los permisos al archivo de jar.

Quedando
de la siguiente manera:

9. Compilar
el archivo .jar en el Hadoop

Sin embargo, en algunas ocasiones, aparecerá un error de que no reconoce la clase y para ello, se tiene que escribir el nombre de la clase apropiada en el comando, en este caso Driver. En programas que solo necesitan de un solo archivo de java, solo se especifica la clase de ese archivo, por ejemplo, el programa WordCount.
En otras ocasiones, será necesario especificar el nombre del paquete junto con el de la clase, para que se pueda compilar como debe ser. Por ejemplo:

Como se puede ver, el código del
programa tiene un paquete, por tanto, ese paquete es el que se debe especificar
cuando se vaya a compilar.

10. Para
finalizar, para ejecutar el programa, se escribe el siguiente comando:

Además, al compararse con los
archivos de entrada, se vera lo siguiente:

Es decir, el numero de veces que
se repite cada uno de las palabras en ambos archivos de texto.
REFERENCIAS
Tutorials Point. (s.f.). Hadoop - MapReduce. Tutorials Point Recuperado de https://www.tutorialspoint.com/es/hadoop/hadoop_mapreduce.htm
Mohammed Sheeha. (Diciembre 2016). How to run Word Count example on Hadoop
MapReduce (WordCount Tutorial). YouTube Recuperado de https://www.youtube.com/watch?v=6sK3LDY7Pp4
Kishore. (Noviembre 2014). Hadoop Java Error. Stack OverFlow Recuperado de https://stackoverflow.com/questions/26700910/hadoop-java-error-exception-in-thread-main-java-lang-noclassdeffounderror-w


Comentarios
Publicar un comentario